
다시 배우는 확률론 (3) - 확률 분포
검색공부하기 :
2007. 5. 6. 23:12 By LiFiDeA
지난회까지 확률의 기본 개념 및 확률과 관련하여 범하기 쉬운 오류에 대해 알아보았습니다. 이번에는 확률 지식을 실전에 응용하는데 기본이 되는 확률분포를 알아보겠습니다. 확률의 개념을 이해하면 됬지 왜 여러 종류의 확률분포를 또 공부해야 되냐구요?
이렇게 생각해봅시다. 객체지향 설계에서 복잡한 요구사항을 디자인 패턴의 조합으로 해결하듯이, 확률분포는 복잡한 실제 현상을 단순한 확률모형의 조합으로 이해하기 위한 도구입니다. 현상을 확률적인 특성에 따라 몇 가지로 구분하고 각각에 대해 필요한 값(확률분포함수, 평균, 분산 등)을 미리 계산해 놓았으니 고맙기 이를데 없습니다.
복잡한 현상을 확률분포 몇가지의 조합으로 분석할 수 있다는 사실도 놀랍거니와, 임의의 확률분포에서 추출한 표본이 정규분포를 따른다는 신비로운 특성도 보입니다.
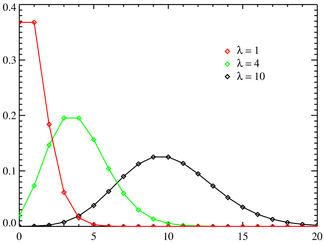 시간당 5명의 손님이 오는 가게에서 일한다고 생각해 봅시다. 바로 이 순간에 손님이 도착할 확률은 0에 가까우나, 순간이 무한히 모여 이루어지는 기간(1시간)에 대해서는 일정한 확률(5명)이 정의됩니다. 이를 표현하는 확률분포가 포아송분포로서, 앞서 살펴본 이항분포에서 성공률이 극히 작은(p->0) 대신 시행횟수가 매우 큰(N->무한대) 경우라고 생각하면 편합니다.
시간당 5명의 손님이 오는 가게에서 일한다고 생각해 봅시다. 바로 이 순간에 손님이 도착할 확률은 0에 가까우나, 순간이 무한히 모여 이루어지는 기간(1시간)에 대해서는 일정한 확률(5명)이 정의됩니다. 이를 표현하는 확률분포가 포아송분포로서, 앞서 살펴본 이항분포에서 성공률이 극히 작은(p->0) 대신 시행횟수가 매우 큰(N->무한대) 경우라고 생각하면 편합니다.
실제 시/공간에서 벌어지는 일은 대부분 여기에 해당되기에, 포아송분포는 쓸모가 많습니다. 예를 들어 일정한 횟수와 분포로 발생하는 사건을 다루는 대기행렬 이론(Queueing Theory)의 기초가 되기도 합니다. 큐잉 이론은 다음 회에서 다시 다루도록 하겠습니다.

k : 사건의 실제 발생 횟수
λ : 단위 기간동안 예상 발생 횟수
위와 같은 포아송분포를 k를 x축으로 갖는 확률분포 그래프로 그리면 위와 같습니다. 그림에서처럼 λ가 4인 경우 4에서 가장 높은 확률을 보입니다. (기간 당 예상 발생 횟수가 4이니 당연합니다.)
사건의 발생 확률이 지수적(exponential)으로 감소하는 분포를 지수분포라고 합니다. 예컨데 단위 길이를 뚫을 확률(강성)이 λ인 금속판을 어떤 입자가 a보다 깊게 뚫는 사건을 생각해봅시다. 이를 두께가 1/n으로 무한히 얇은 금속판을 n*a번 뚫는 사건으로 볼 수 있으며, 이에 따른 확률분포는 아래와 같습니다.
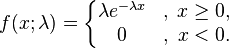
중심극한정리를 모집단과 표본집단의 관계를 설명하는 것으로 이해할 수 있는데, 모집단을 모두 조사하기 힘든 경우 표본 조사를 수행하고 이를 통해 모집단의 평균 및 분산을 역으로 추정할 수 있는 것입니다.
중심극한정리를 이해하면 정규분포가 왜 그렇게 광범위하게 나타나며, 또한 활용되는지 알 수 있습니다. 많은 현상이 단일 확률분포를 따른다기보다 확률분포에서 추출된 여러 값의 합으로 묘사될 수 있는데, 이 합은 어김없이 정규분포를 따르기 때문입니다. 따라서 자연계의 현상(예:신호의 노이즈) 분석 및 표본추출에 근거한 사회현상 분석에는 대부분 정규분포가 사용됩니다.
이렇게 생각해봅시다. 객체지향 설계에서 복잡한 요구사항을 디자인 패턴의 조합으로 해결하듯이, 확률분포는 복잡한 실제 현상을 단순한 확률모형의 조합으로 이해하기 위한 도구입니다. 현상을 확률적인 특성에 따라 몇 가지로 구분하고 각각에 대해 필요한 값(확률분포함수, 평균, 분산 등)을 미리 계산해 놓았으니 고맙기 이를데 없습니다.
복잡한 현상을 확률분포 몇가지의 조합으로 분석할 수 있다는 사실도 놀랍거니와, 임의의 확률분포에서 추출한 표본이 정규분포를 따른다는 신비로운 특성도 보입니다.
이항분포(Binomial Distribution)
가장 단순한 확률분포로, 앞면이 p의 확률로 나오는 동전을 N번 던졌을 때 나오는 앞면의 개수가 이루는 확률분포입니다. 앞면 혹은 뒷면으로 결과를 구분할때와는 달리 결과가 숫자이므로, 이를 좌표평면에 표시할 수 있습니다. 기본 조건인 동전의 성질(p)와 시행 횟수만 알면 평균은 Np, 분산은 Np(1-p)로 구해집니다.포아송분포(Poisson Distribution)
시간당 5명의 손님이 오는 가게에서 일한다고 생각해 봅시다. 바로 이 순간에 손님이 도착할 확률은 0에 가까우나, 순간이 무한히 모여 이루어지는 기간(1시간)에 대해서는 일정한 확률(5명)이 정의됩니다. 이를 표현하는 확률분포가 포아송분포로서, 앞서 살펴본 이항분포에서 성공률이 극히 작은(p->0) 대신 시행횟수가 매우 큰(N->무한대) 경우라고 생각하면 편합니다.실제 시/공간에서 벌어지는 일은 대부분 여기에 해당되기에, 포아송분포는 쓸모가 많습니다. 예를 들어 일정한 횟수와 분포로 발생하는 사건을 다루는 대기행렬 이론(Queueing Theory)의 기초가 되기도 합니다. 큐잉 이론은 다음 회에서 다시 다루도록 하겠습니다.
λ : 단위 기간동안 예상 발생 횟수
위와 같은 포아송분포를 k를 x축으로 갖는 확률분포 그래프로 그리면 위와 같습니다. 그림에서처럼 λ가 4인 경우 4에서 가장 높은 확률을 보입니다. (기간 당 예상 발생 횟수가 4이니 당연합니다.)
지수분포(Exponential Distribution)

지수분포는 무기억성(Memoryless)이라는 고유의 특성을 갖는데, 이는 과거의 사건이 미래에 영향을 끼치지 못한다는 의미입니다. 예를들어 전구가 켜져있는 시간이 지수분포에 따른다면, 10(s)시간동안 켜져있던 전구가 11(s+t)시까지 켜져있을 확률이 새 전구가 1(t)시간 켜져있을 확률과 같다는 뜻입니다. 이를 식으로 정리하면 아래와 같습니다.

이 성질은 지수분포가 다양한 현상을 모델링하는데 사용되는 이유가 되니, 잘 알아둡시다.정규분포와 중심극한정리(Central Limit Theorem)
이공계 대학생이라면 누구나 배우는 것이 중심극한정리입니다. 요약하면 임의의 서로 독립적인 확률분포(모분포)에서 추출된 값들의 합(표본 평균)은 원래 모분포의 종류와 관계없이 정규분포를 이룬다는 겁니다. 다음 웹페이지에는 다양한 모분포에 대해 표본 평균이 정규분포가 됨을 애니메이션으로 보입니다. 이때 정규분포의 평균은 모분포의 평균과 동일하나, 분산은 모분포의 분산을 추출한 횟수(표본 크기)로 나눈 값입니다. (여러번 추출하여 평균한 값에 대한 분포이니 당연히 분산이 줄어들게 됩니다.)중심극한정리를 모집단과 표본집단의 관계를 설명하는 것으로 이해할 수 있는데, 모집단을 모두 조사하기 힘든 경우 표본 조사를 수행하고 이를 통해 모집단의 평균 및 분산을 역으로 추정할 수 있는 것입니다.
중심극한정리를 이해하면 정규분포가 왜 그렇게 광범위하게 나타나며, 또한 활용되는지 알 수 있습니다. 많은 현상이 단일 확률분포를 따른다기보다 확률분포에서 추출된 여러 값의 합으로 묘사될 수 있는데, 이 합은 어김없이 정규분포를 따르기 때문입니다. 따라서 자연계의 현상(예:신호의 노이즈) 분석 및 표본추출에 근거한 사회현상 분석에는 대부분 정규분포가 사용됩니다.
참고자료
강의자료
통계 정보 홈페이지 (전북대 통계정보학과 / 친절한 설명이 인상적입니다.)
확률론과 확률분포
표본이론과 중심극한이론
확률분포
http://en.wikipedia.org/wiki/Probability_distribution
http://en.wikipedia.org/wiki/Binomial_distribution
http://en.wikipedia.org/wikiPoisson_distribution
http://en.wikipedia.org/wiki/Exponential_distribution
중심극한정리
http://en.wikipedia.org/wiki/Illustration_of_the_central_limit_theorem
http://en.wikipedia.org/wiki/Concrete_illustration_of_the_central_limit_theorem
중심극한정리 컴퓨터 시뮬레이션
(모든 그림은 위키피디아에서 차용하였습니다.)
'검색공부하기' 카테고리의 다른 글
| 다시 배우는 선형대수(1) - 우리곁의 벡터와 행렬 (11) | 2007.05.20 |
|---|---|
| 다시 배우는 확률론 (2) - 통계의 함정 (1) | 2007.04.24 |
| 다시 배우는 확률론 (1) - 기본 개념 (6) | 2007.04.22 |



